
BACKGROUND
For over twenty-five years Intellisophic has supplied semantic data called taxonomies to customers in legal, health, national security and regulatory sectors. In response to 9/11, Intellisophic was competitively chosen to build the foundation of 21st centry counterintelligence systems providing global terrorist activity analysis based on open web intelligence. The reason was our invention and development of software that automated human understanding, performing at the highest levels of precision required by real world users.
Our DevOps team with over 50 semantic AI engineers is founder led supporting pharma, national intelligence, document management and legal discovery customers on a global level.

We are emerging from a stealth protected anonymous technology provider to a semantic AI leader with proven battle-tested scale success. There are at least two AI models represent different approachs with a common history and purpose. Both started at MIT sixty-five years ago. Our technical white papers and observations developed over the past two years support a hybrid-model.
The Face of Semantic AI Leadership
The MIT Foundation (1964-1970)
Our founder, George Burch, began his AI journey in 1964 at MIT’s Artificial Intelligence Laboratory. He was a member of the Operations Evaluation Group
Working with pioneers like John McCarthy, he learned to use Lisp to build symbolic AI systems that manipulate meaningful symbols rather than just statistical patterns. His breakthrough came in 1965 when he solved a critical Cold War defense scenario by combining semantic understanding with operational research, earning recognition at the Military Operations Research Society Symposium.

During the Vietnam War, Burch applied these techniques to counterintelligence, developing models that disrupted enemy supply lines. His work earned a Presidential commendation and proved that AI could deliver results in life-or-death situations.
Building Commercial Applications (1970-2000)
After government service, Burch pursued a simple vision: bring semantic AI’s precision to commercial challenges.
In the 1970s, he helped the U.S. Census Bureau process geographic data at unprecedented scale, developing early pattern recognition systems that could transform massive image datasets into usable information.
The 1980s brought a focus on data quality. Burch created “Integrity,” a solution that ensured database queries returned meaningful results by aligning data structure with intended meaning. This product became the foundation of the enterprise data quality industry and was eventually acquired by IBM.
In the 1990s, Burch and his team made a crucial discovery: textbooks contain structured knowledge perfect for training semantic AI systems. They patented methods to automatically extract this knowledge and partnered with publishers like Britannica and O’Reilly to create the first “surfable books.”
Scaling Semantic Understanding (2000-Present)
After 9/11, Intellisophic’s semantic technology became the foundation for next-generation counterintelligence systems. While others focused on keyword matching, our systems understood context and meaning, enabling analysts to identify threats from vast amounts of open-source intelligence.
Throughout the 2010s, we quietly indexed the modern web—social media platforms, news archives, and specialized databases—building the world’s largest semantic understanding of human knowledge. Our taxonomy grew from 500,000 to over 8 million interconnected concepts.
Orthogonal Corpus Indexing: The invention that solved the AI scale problem.
The Intellisophic team began work on an invention, granted provisionary status in April 1999. Orthogonal Corpus Indexing (OCI)

In 1991 Sir Timothy Berners-Lee launched the World Wide Web (WWW) by creating the Hypertext Transfer Protocol (HTTP) currently referred to as Web 1.0. A few years later Sir Tim working at the MIT AI Laboratory created a semantic AI model of human understanding based on the concepts and facts humans use to fact check and reason. Sir Tim’s W3C Reference Data Framework Protocol, later known as the semantic web 3.0, presented any AI a major practical problem: the meaning of the data humans read was understood only by humans. Efforts like the CYC project demonstrated that it was effectively impossible to load the worlds knowledge into a taxonomy database by hand.
By 1996 there were 6 million website domain names with over 250 million URL serving 36 million global users. Today these statistics are measured in billions.
George formed the Intellisophic team in 1996 based on the observations that automating hand made ontologies was the solution required to scale AI.
The patent described the purpose: “Today there is a need for a ‘table of content’ for the World Wide Web.”

Note: the latency was long back then too.
The resulting product wa lm called Indraweb, Information Directory for Research and Access to the Web.
CIFA/JCAG Multi-domain Open-Source Analysis and Exploitation Center MOSAEC: Building a Network of Domain-Specific Knowledge
The rapid growth of open source content on the web required a reassesment of national defense counterintelligence that led to the founding of Intellisophic.
Intellisophic’s DeepMeaningAI stack
Intellisophic’s Semantic AI is the Foundation of the Nations Counterintelligence Infrastructure

Defense Information and Electronics Report (Copyright) August 6, 1999:
“JCAG will form the nucleus of Defense CI’s support of the department’s research and technology protection program.
“Intellisophic’s semantic AI was deployed by the Joint Counterintelligence Assessment Group (JCAG) in 2003. The purpose was to provide global terrorist activity analysis based on open intelligence and internal agency documents.
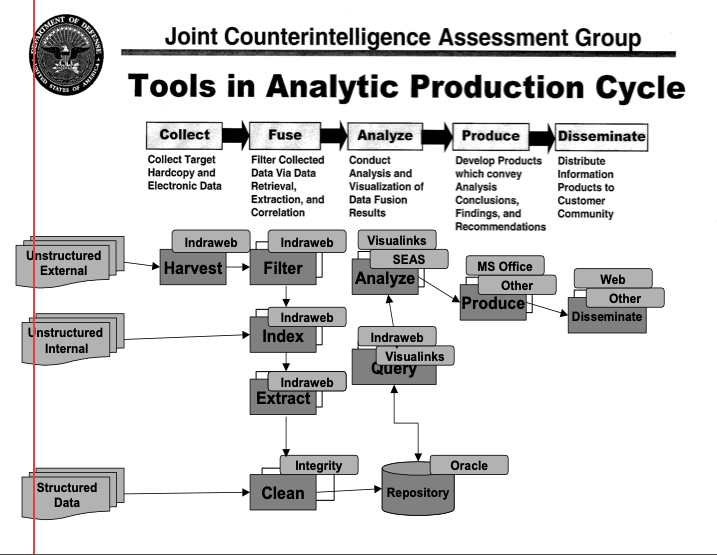
The MOSAEC CI Product
CIFA the Multi-domain Open-Source Analysis and Exploitation Center, or MOSAEC. MOSAEC’s initial operating capability (IOC) was demonstrated to CIFA officials on 19 August 2003 and briefed to the Under Secretary of Defense (Intelligence and Security) on 21 October 2003.”
“The purpose of the MOSAEC system is to provide various knowledge bases on specific intelligence, counterintelligence, and counterterriorism domains of interest as a desktop resource for CIFA analysts and other US Government end-users. As more and more information is made available electronically via the Web and other means, and as the volume of relevant data from global, non-traditional sources continues to increase, so does the challenge of efficiently making sense of it. As a consequence, the vast array of open-source information remains an abundant, but as yet untapped, resource. MOSAEC is geared toward providing CIFA analysts with an enhanced ability to exploit this information systematically, thereby improving the capability to identify and assess existing and emerging threats by improving the overall supply of relevant data collected from the Web and other sources, and as a result, increasing the collective “knowledge capacity” of CIFA.
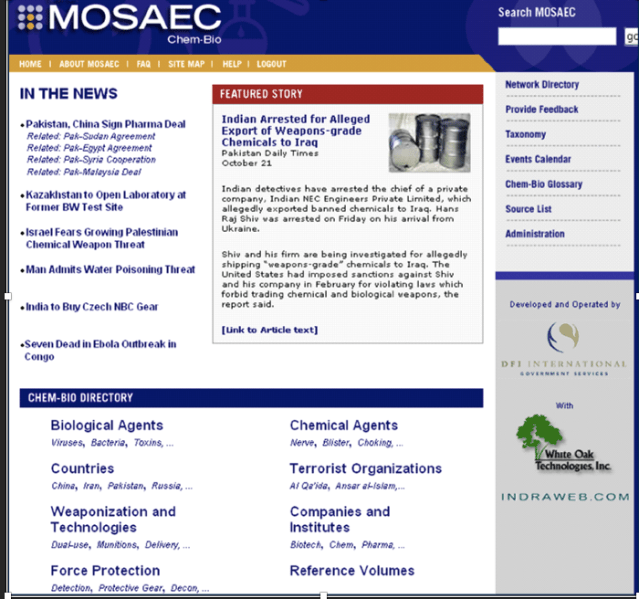
DFI completed development of the MOSAEC Chem-Bio portal, to include attaining initial operating capability, in 2003. In 2004, the Chem-Bio system will be transitioned to full-time operational status, pending resolution of the specific technical architecture required. Indraweb provided the Chem-Bio concept library.” This is what the
This portal was not public. The arrest in the featured story was based on the JCAG intelligence production powered by Indraweb. The 11,000 Chem-Bio taxonomy sources are shown below. The taxonomy was used to navigate the MOSEAC Chem-bio directory. Indraweb is credited on the right hand side of the portal.
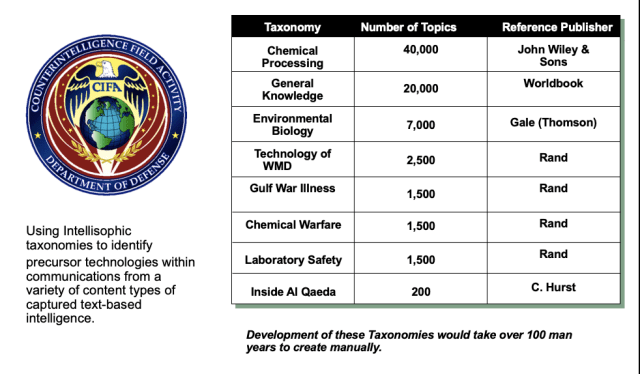
A critical need filled by Intellisophic was red-team analysis. Thousands of scenarios were constructed by CI experts with semantic understanding of the red-team text embedded in Indraweb’s logic layer. The source of knowledge wa
Indraweb became the backbone of the DoD/CI executive branch response to the 9/11 terrorist attck
“The mission of the DoD CIFA is to develop and manage DoD Counterintelligence (CI) programs and functions that support the protection of the Department, including CI support to protect DoD personnel, resources, critical information, research and development programs, technology, critical infrastructure, economic security, and U.S. interests, against foreign influence and manipulation, as well as to detect and neutralize espionage against the Department.
The principal measure of success in meeting mission objectives will rely heavily on searching through potentially billions of publicly available documents (over 4 billion web pages) as well as additional millions of DoD communications and documents in order to identify areas at risk.”
The following slide describes the reason for selecting Vendor 1 for further testing and implementation.
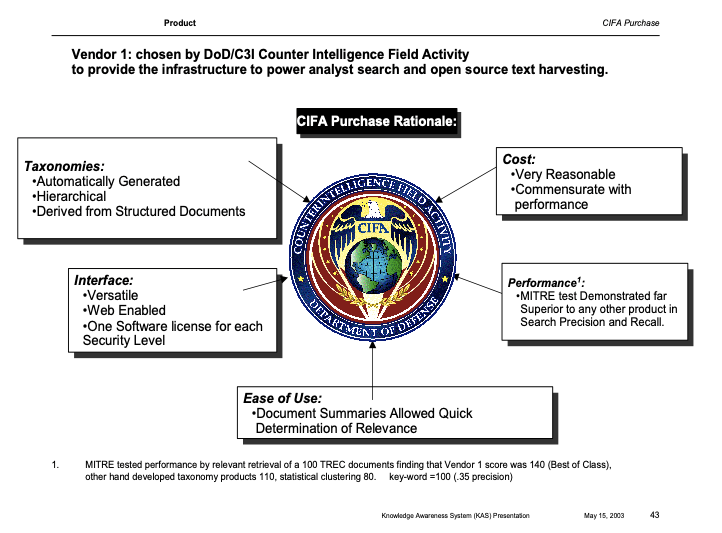
CIFA tested the major vendors including an In-Q-Tel knowledge management company (Verity) and an industry leading search software (Convera). In terms of performance the clear winner was a system based on automated large scale taxonomies (Indraweb).
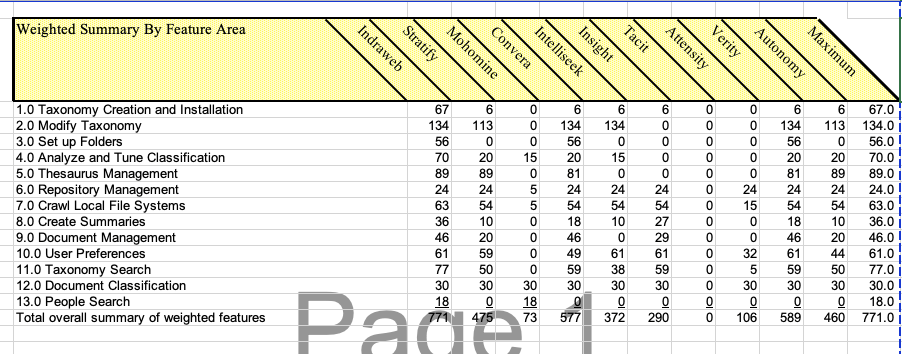
Intellisophics competition listed on the score card below were all world class and well known. Autonomy and Verity had a $14B market value. Intellisophic consistently was best in category by large margins with a team of 10 developers. Two decades later the team has grown to over 100 semantic Ai engineers serving specific global enterprise knowledge domains in Pharma, Legal, Document Management and others.
Performance

Intellisophic dominated the competition in every TREC category.

Intellisophic fine tuned to the application need for domain expertise.
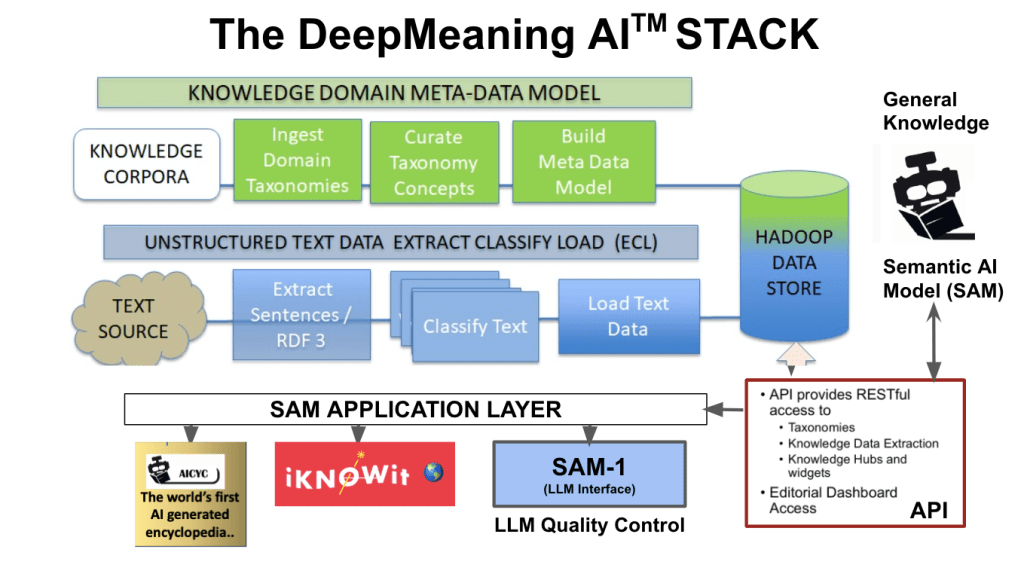
Intellisophic began developing the foundational semantic AI model (SAM) under the trade name Indraweb
BACKGROUND
In 2001 Sir Tim coined the term the semantic Web 3.0 to describe an intelligent web that understands the meaning and context of words.

Our first commercial application was the sBook project using OCI to semantically index published text book knowledge. The first publisher beta was an encyclopedia. The publisher Tim O’Reilly was an early Indraweb partner and coincidentaly popularized the term Web 2.0 in 2004.

