The foundation of modern AI was established in 1999 by Intellisophic Founders Burch, Kon and Hoey
The foundation was based on using the world’s reference corpora and text books to build a knowledge graph meta-data model based on Berners-Lee semantic web 3.0 using automation to overcome the cost barrier of using humans in the process.

The road block to AI success since its beginning in the 1950s is not models. It is coding knowledge by hand. The patent proposed a solution that mined knowledge from text books to load data into a logic based system similar to a relational database model using Extract-Transform-Load (ETL) software.
What Intellisophic actually built, when everyone else is still trying to work around the cost of humans-in-the-loop, was software. To test the software a user interface was developed called S-Books. The first S-Book partner was the World Book Encyclopedia. Publishers of over 80% of English language reference corpora participated in the S-Book project. The wayback machine link below provides the look and feel of the 2001 demo.

Our publisher partners increased and provided unprecedented access when Intellisophic’s AI was chosen as the platform to build counterintelligence warfare systems
The Counterintelligence Field Activity (CIFA) documentation shows the superiority of semantic AI technical architecture.
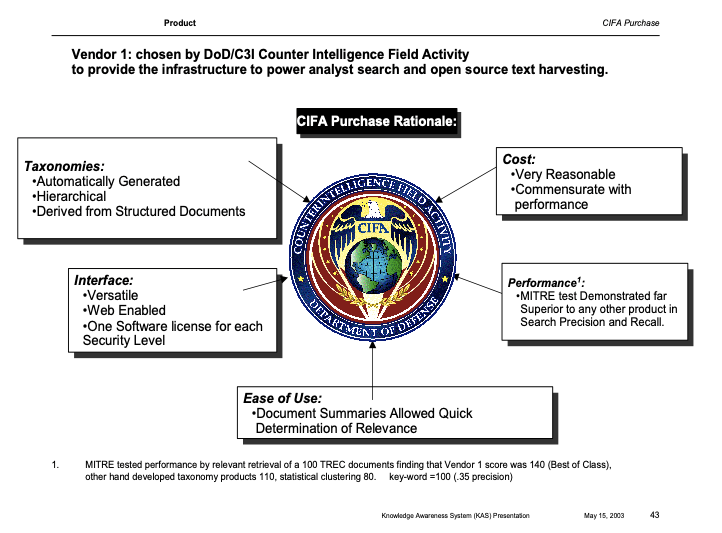
Indraweb, Intellisophic’s original name, was selected as the Foundational AI for 21st Century Counterintelligence against hand coded and statistical methods. No competition has emerged from generative AI due to technical quality failure. The leading AI suppliers that competed with Intellisophic/Indraweb (vendor 1) are listed on this score card,
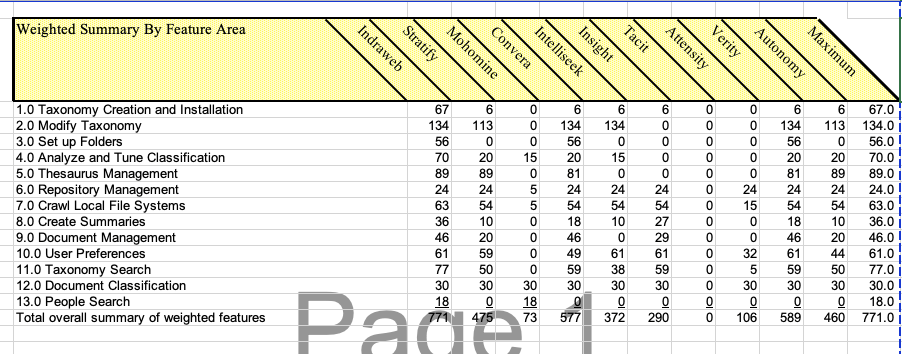

No foundational AI Large Language Model (LLM) has demonstrated fitness for any national security role while real AI is built on a proven stack.
What Others Built (Statistical Approach):
- Keywords → Document matching
- Term frequency/inverse document frequency (TF-IDF)
- Probabilistic retrieval models
- Essentially sophisticated pattern matching
What Intellisophic Built (Semantic Approach):
- Concepts → Meaning networks → Document understanding
- Automated taxonomy construction from authoritative sources
- Multi-dimensional semantic relationships
- Actual comprehension of content
The Technical Differentiator
Looking at the MOSAEC Chem-Bio portal example:

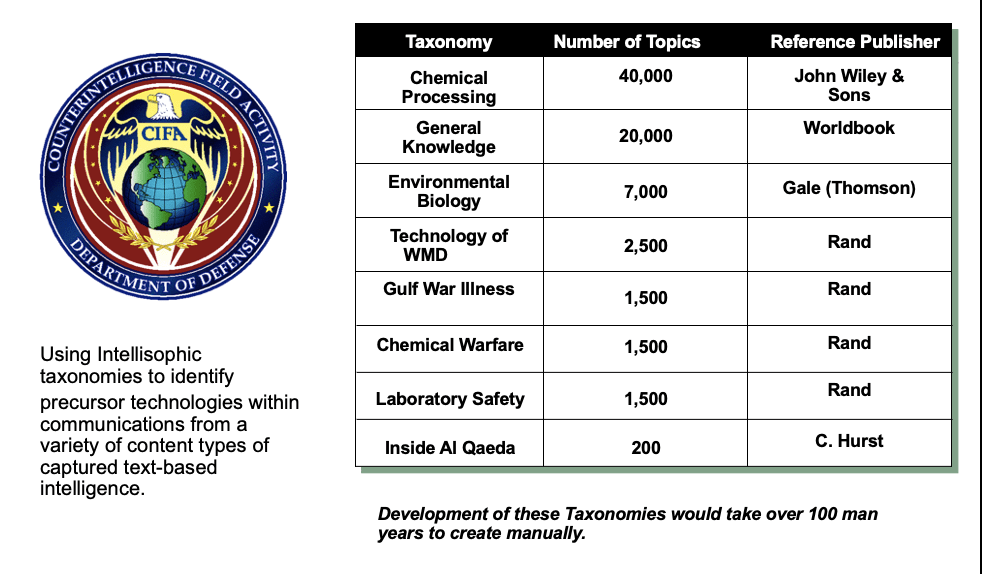
- Unlimited taxonomy concepts – not keywords, but semantically validated concepts
- Each concept linked to authoritative knowledge (textbooks, technical manuals)
- Hierarchical relationships that mirror expert understanding
- Cross-domain linkages that capture real-world connections
The “Orthogonal” Breakthrough:
Traditional indexing is one-dimensional: word → document. Intellisophic’s approach is multi-dimensional:
Why This Produced Superior Precision
1. False Positive Elimination
When searching for “anthrax” in a bioterrorism context:
- Statistical systems return every document mentioning “anthrax”
- Intellisophic’s semantic system understands context: anthrax (weapon) vs anthrax (veterinary disease) vs anthrax (industrial exposure)
2. Implicit Knowledge Capture
- Experts don’t always use the exact query term. A bioweapons analyst might discuss spore viability, aerosolization efficiency, LD50, or protective antigen without saying “anthrax.”
- OCI maps these related concepts through semantic links (taxonomy + cross-domain relations), retrieving the right documents because it understands “anthrax-as-weapon” via its properties, processes, and implications—not just the word.
3. Query Disambiguation and Expansion
- Disambiguation: “Smallpox” in immunology vs. biosecurity contexts leads to different result sets and weights (vaccine stockpile policy vs. poxvirus replication).
- Expansion: User queries auto-augment with semantically adjacent concepts (vaccinia, variola major/minor, ring vaccination, BSL-4 protocols), improving recall without sacrificing precision.
4. Provenance-Weighted Scoring
- Because each concept is tied to authoritative sources, scoring can weight documents by the strength of their linkage to vetted knowledge, not just term frequency.
- This curbs noisy web chatter and promotes content aligned with expert literature.
5. Multi-Axis Ranking
- Vertical signals: placement in a concept hierarchy (specificity and inheritance).
- Horizontal signals: cross-domain bridges (e.g., chemistry ↔ industrial safety ↔ environmental law).
- Temporal signals: currency and evolution (post-event advisories vs. historical accounts).
- Contextual signals: domain sense of terms, document genre, and intended audience.
6. Why This Was Orthogonal (and Not Just “Better TF-IDF”)
- Representation: index keys are concepts with typed relations, not untyped tokens.
- Inference: retrieval uses graph traversal and constraint satisfaction across dimensions, not bag-of-words similarity.
- Learning: taxonomy construction leverages authoritative sources to induce structure; models then propagate meaning via relationships.
- Maintenance: concept drift handled by temporal dimension updates and re-linking of entities as definitions evolve.
7. Concrete Retrieval Flow (Anthrax-as-weapon example)
- Parse query → detect domain “bioterrorism.”
- Activate concept subgraph: Bacillus anthracis (weaponization) → spore properties → aerosol dissemination → decontamination protocols → PPE → CDC Category A agent.
- Filter out veterinary-only and occupational exposure nodes unless explicitly requested.
- Rank by:
- Proximity in the concept graph to “weaponization”
- Authority provenance (e.g., CDC, DoD manuals, peer-reviewed reviews)
- Temporal recency for advisories and SOPs
- Cross-domain relevance (public health policy, emergency response)
8. Evidence of Scalability (MOSAEC Chem-Bio)
- 72,000 taxonomy sources as ground truth seeds enable breadth with consistent semantics.
- Cross-domain links allow questions like “industrial disinfectants effective against spore-formers in hospital HVAC systems” to resolve across chemistry, microbiology, and facilities engineering.
- Current scale is tens of millions of concepts.
Strategic Takeaways
- Precision comes from context-aware concept disambiguation and provenance-weighted scoring.
- Recall is preserved via semantic expansion along validated relationships—not generic synonym lists.
- The architecture is resilient to vocabulary mismatch and domain-specific jargon, enabling expert-grade search and discovery.
