
You can’t manage what you can’t measure.
You can’t measure what you don’t know.
Enterprise Knowledge consists of the concepts and ideas that form the meaning of a business: its customers, its products, its markets, its advertising, its people, its IP, its agreements, its regulations, and its knowledge of competitors. Intellisophic mines knowledge nuggets about your business and stores the results in a Knowledge Graph.
Knowledge Graphs Mean Business
Enterprise knowledge created by humans is stored as unstructured data, sometimes called Dark Data. The knowledge is located in documents such as contracts, website page, power-point slides, email, text messages, customer notes, and social media communications.
Humans understand this unstructured content by reading text and assigning meaning to what they read. The problem is the context and meaning is implicit and stored in the mind of the knowledge worker. This knowledge data is not generally available for analysis due to the high cost of human knowledge tagging and coding.
This white paper describes how the Intellisophic platform automatically extracts knowledge from unstructured data and loads that knowledge into a relational data store or Hadoop data lake for analysis and decision making.
Our technology is different from ordinary neural networks and machine learning AI. We call it DEEP MEANING AITM because it is based on semantics not statistics.
KNOWLEDGE GRAPHS MEET W3C STANDARDS
Deep Meaning AI is architected to conform to the Resource Description Framework (RDF) Standards of the W3C semantic web. The W3C architecture provides for machine use of the knowledge data extracted by our technology.

Semantic Web 3.0
- Knowledge graph constructor.
- Text classifier.
- Fact extractor.
Intellisophic’s DeepMeaning AI technology platform automates the discovery and management of enterprise knowledge. Our background as leaders in ETL and Data Quality for structured data has provided the patented methodology for extracting knowledge data from unstructured content.
Knowledge Graphs

Automated Knowledge Graph Construction
As shown in the diagram below the knowledge data model behind Deep Meaning AI is a taxonomy of concepts. The organization and context of the concept is contained in the taxonomy hierarchy. The concept is defined by “matching rules”: the words and phrases that identify the concept in an unstructured data source.
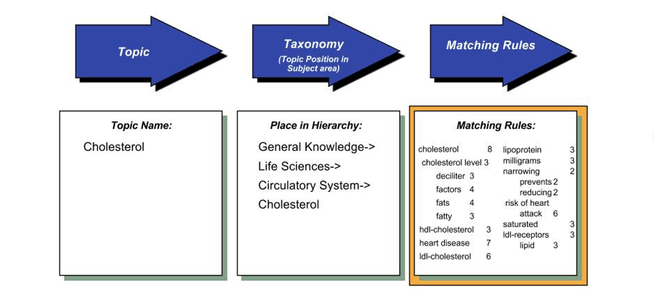
Taxonomy Meta-Data Structure
Taxonomies provide the semantic meta data needed to define knowledge for machine use. Unstructured data is built for humans to read. expresses meaning using semantic concepts (topics) and context. The concept is used by machines to understand and model organizational knowledge. Context is the graph path to a concept stored as a node in the Knowledge Graph (Taxonomy) ,
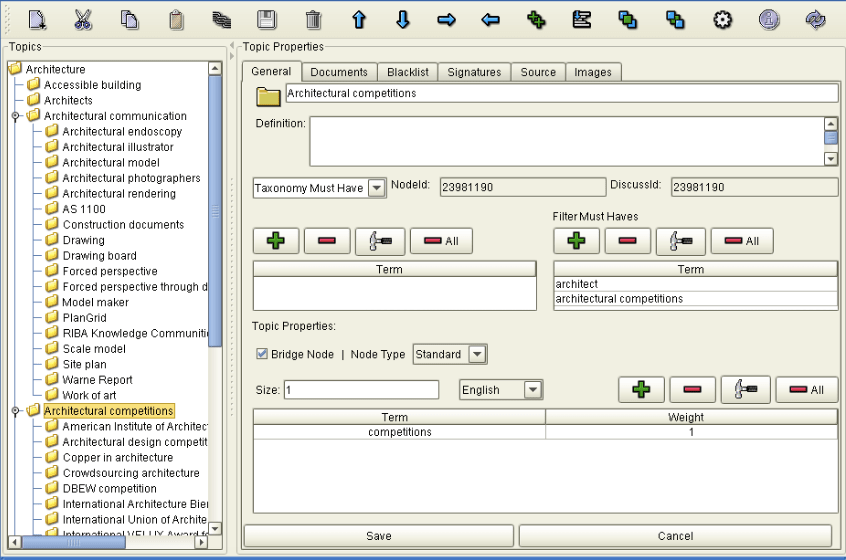
Taxonomy Editing Panel
The editor dashboard provides taxonomy creation and editing, taxonomy export and import, Library search, and automatic taxonomy creation from reference publications (Knowledge Corpora) .
The Knowledge Corpora is defined as reference books, manuals and encyclopedias, Our publisher partners provide the legal rights to process their copyrighted works. Currently over 80% of reference corpora publications in English have licensed their taxonomy rights to Intellisophic. Our publishing partners include:
- Gale,
- Britannica,
- Elsevier,
- O’Reilly,
- McGraw-Hill, and
- John Wiley
Intellisophic’s taxonomy library is one of the largest in the world. Our Technology enables new fields of knowledge specific to the enterprise to be rapidly developed and deployed from domin specific corpora.

Taxonomy Catalog Description
Ontologies

Factual Knowledge Extraction
Deep Meaning AI uses Natural Language Processing (NLP) algorithms to extract sentences and transform them into the RDF grammatical expressions called “triples” (Subject, Predicate, Object). The RDF triple is converted into the Ontology for specific knowledge domains. The RDF-triples are the common sense facts specific to a business industry.
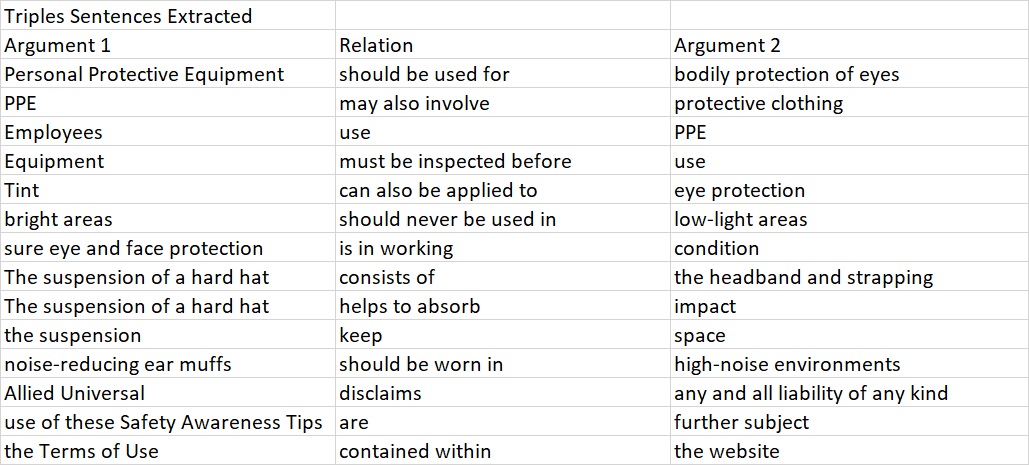
RDF-triple Example
The Ontology constructor identifies the relationships linking taxonomy topics. The ontology data is specific to the taxonomy source.
The Deep Meaning AI platform creates information rich knowledge data triples, the ontology, for semantic search and intelligent agents. RDF triples are a kind of story board for chatbots and intelligent agents (IA). In the example above a training document regarding protective gear was transformed into RDF triples. This process enables an IA to “understand” a question like “Where should ear-muffs be worn?” with the answer, “In high-noise environments.” This knowledge data also is used to extend knowledge by inference.
Taxonomy and Ontology Data
There are four basic data elements that the Deep Meaning AI platform extracts from unstructured data and loads into a Hadoop data store, data lake or data warehouse. These data elements are shown below as a table. The COLUMN is a particular node in the Knowledge Graph. The ROWs of the model are the specific information sources within a text document containing the data. Essentially the Deep Meaning AI data model can be understood as a relational data model. In practice the context hierarchy tree is stored as a directed graph in a no-sql database such as S3 in AWS.
- The concept is the context for human meaning and understanding.
- The sentence is the human interface to the facts contained in text.
- Images are used to help communicate the topic of interest and for cross-lingual applications.
- The RDF triple is a machine readable “fact” extracted from a sentence as Ontology data used in fact checking content.
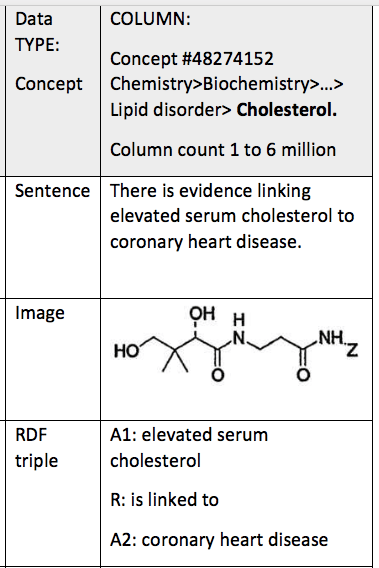
The knowledge extracted from text is linked to a specific document and to the specific sentence or image within the document using a Uniform Resource Identifiers (URI). The URIs identify the source of the knowledge data and provide the exchange standards for accessing meaning by other machines using the W3C Semantic Web 3.0 Reference Data Framework (RDF)
Enterprise Knowledge Data Processing
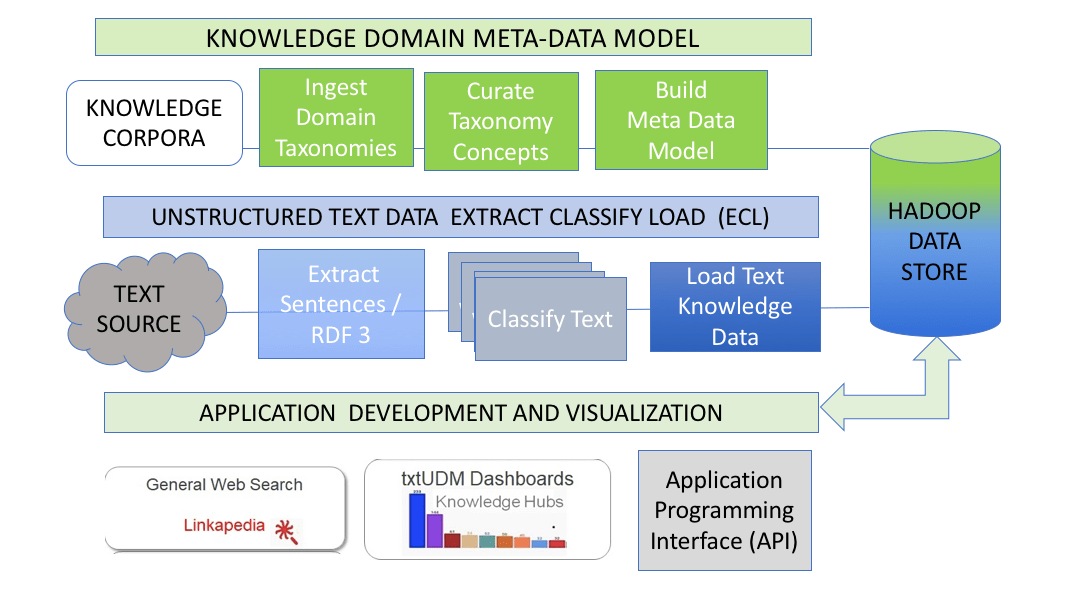
WORKFLOW
- Ingest Knowledge Sources.
- Select Data sources.
- Extract and Load Knowledge Data.
- Application Programming Interface (API)
Extracting Knowledge Data From Text.
- Building Knowledge Domain Meta-Data Models.
- Extracting Knowledge Data from Unstructured Text (ECL).
- Developing Applications Using APIs and Visualization.
- Building Vertical Knowledge Domains.
We couple our taxonomic assets with world class classification technology. Our classification engines run in AWS’s cloud in large MapReduce clusters. These clusters process billions of documents against millions of rules and store all the data in real time in a large no-sql database that loads the knowledge data into an enterprise data store or feeds real time applications.
Application Programming Interface. (API)
The platform is accessed through Intellisophic’s Deep Meaning application programming interface (API). See code sample below.
Development tools and Devops are designed to meet most application requirements based on Agile development. The technology can be delivered as Software installed in the partner computing environment for high security applications or the APIs can be accessed through a SaaS Cloud Platform (AWS).

API Code Example
Application Development and Visualization.
Intellisophic provides out-of-the-box knowledge data solutions and visualization tools supporting the taxonomy development and classification technology described above.
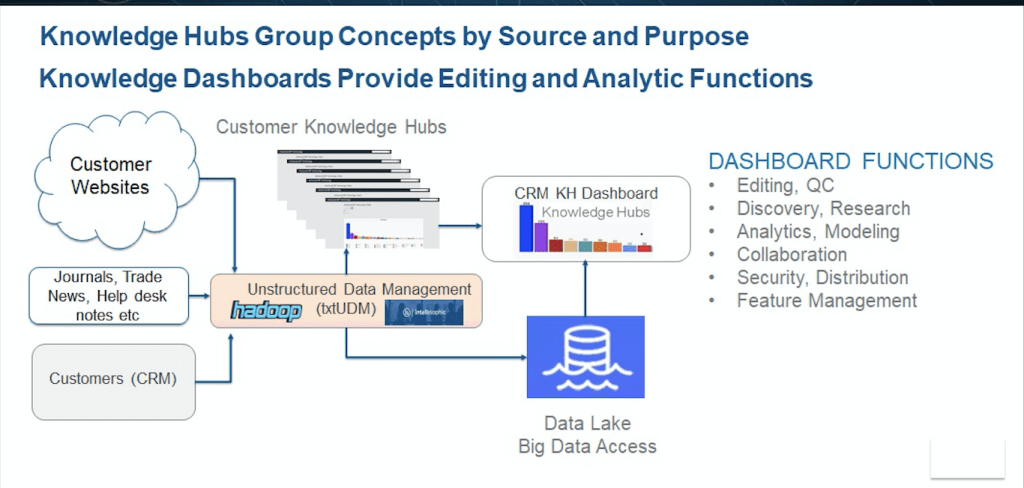
Knowledge Hub Explorer.
The most basic view is a histogram of concepts based on document sources. The following diagram shows a corporate web site and blog concepts related to Computing knowledge domain. The numbers represents the number of times the knowledge sub-category is found in a document source. Each histogram topic can be further expanded to quickly browse content.
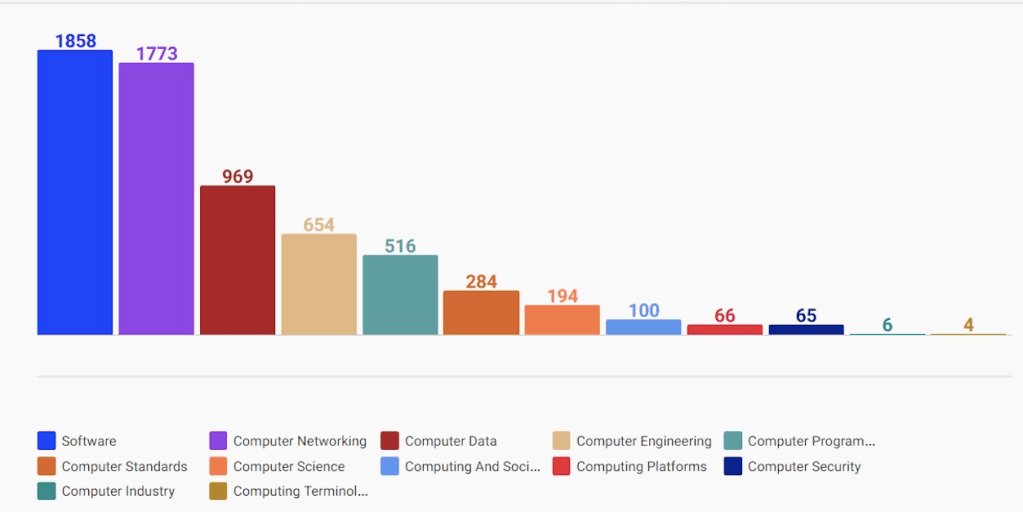
Concept Visualizer
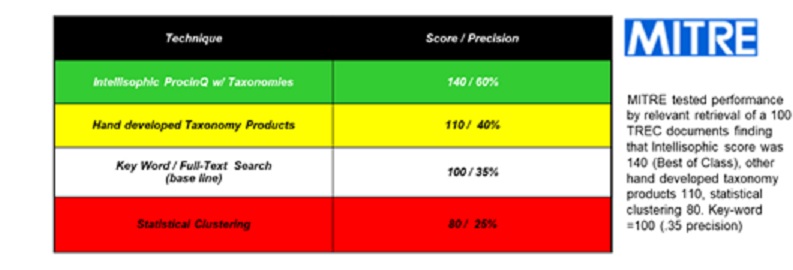
External Performance Certification.
The most comprehensive test of semantic AI is conducted by the Federal Government. The purpose is to measure the ability of technology to classify documents. It is an open contest. Intellisophic results as measured by Mitre on behalf of the National Institute of Standards and Technology (NIST) Text REtrieval Conferences (TREC) are at the highest level of performance ever measured.
Customer Experience
Over the past decade Intellisophic has employed its patented Deep Meaning AI algorithms to extract meaning from text for major solution providers. Our customers have used Intellisophic products to extract knowledge from billions of documents.

COMPETITIVE ADVANTAGE.
There are dozens of software and service companies that provide unstructured data extraction or text analytic software and services. Many of them partner with Intellisophic or buy our taxonomy products. The principal litmus test is scalability for enterprise wide solutions and OEM use. Our pre-built taxonomy library and automated taxonomy constructors saves as much as 90% of the time and cost to startup over manual based solutions. Our knowledge data extraction is proven to process millions of documents at a fraction of the time and cost for most semantic tools.
END
About Us:
Our technology story is built on decades of data management ETL development experience and a skilled technical team of cloud and agile developers. If you are a vertical solution provider let us show you how to add knowledge to your product.
Contact Us To Learn More:


